AGENTIC SOLUTION
From 30-Minute Waits to Instant Translation in Emergency Care
A healthcare facility serving diverse patient populations collaborated with Antematter to eliminate recurring interpreter expenses and 15-30 minute wait times by deploying an offline-first medical translation system across emergency and outpatient workflows.
Client Background
A medical facility serving diverse patient populations confronted the limitations of traditional interpreter services: scheduled availability creating emergency workflow disruptions, minimum billing windows regardless of actual usage, and per-session costs compounding across thousands of annual encounters. The constraint extended beyond economics. Third-party coordination introduced privacy vulnerabilities and delayed time-sensitive decisions in acute care settings.
Language barriers between healthcare providers and patients create immediate operational friction in clinical delivery. Miscommunication during symptom assessment, medication instructions lost in translation, and critical information gaps during emergency intake delay or disrupt patient care. For facilities serving multilingual patient populations, each untranslated interaction represents measurable risk.
Problem Statement
Language service dependencies created three compounding friction points in clinical operations. Per-encounter interpreter costs ranging from $45-150 per hour for in-person services, $1.25-3.00 per minute for telephonic interpretation, accumulating across patient volume. Wait-time inefficiencies averaging 15-30 minutes per request in emergency departments, directly impacting bed turnover rates and triage throughput. Privacy architecture complications from external service provider integration, requiring ongoing compliance oversight and expanding the attack surface for protected health information handling.
Our Solution
We deployed an on-premises medical translation platform eliminating external interpreter dependencies.The architecture positions AI inference models to run locally on facility hardware, processing 100+ languages locally with sub-2 second response time while maintaining zero data transmission outside of facility bounds.
Key Features and Clinical Integration
Real-time translation capacity scales across clinical urgency tiers:
1-2 second response windows for emergency triage and rapid assessment protocols,
2-4 second processing for standard consultation workflows, and
3-6 second translation for complex procedure explanations and informed consent discussions.
Medical vocabulary coverage extends across 100+ languages with healthcare-specialized terminology databases encompassing anatomical nomenclature, symptom descriptors, pharmaceutical classifications, and procedure-specific lexicons.
Privacy architecture isolates all processing within facility hardware with zero external data transmission, complete HIPAA alignment through design rather than policy layer. Post-deployment internet independence eliminates connectivity as a clinical dependency, ensuring consistent availability during network disruptions or in bandwidth-constrained deployment scenarios.
The translation system deploys at critical communication junctures within existing clinical systems:
Emergency triage stations: First-contact patient assessment replacing phone interpreter queuing
Bedside tablets: Real-time consultation translation during physician rounds and nursing care
Outpatient examination rooms: Consultation workflow integration via existing tablet infrastructure
Discharge planning: Medication instruction and follow-up care communication without scheduling delays
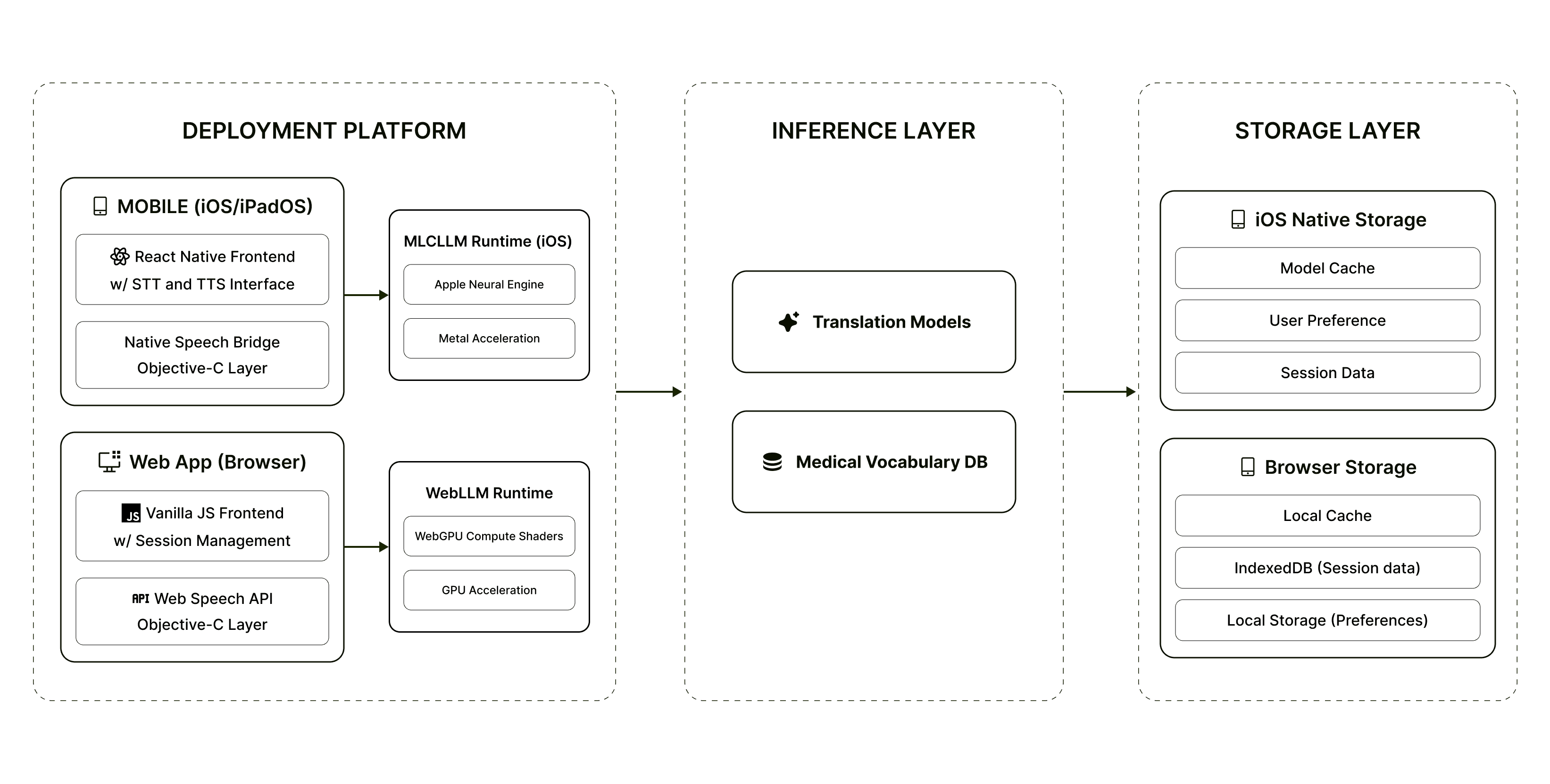
Technical Architecture
Three-tier inference model: Quick Mode (sub-2s emergency scenarios), Professional Mode (2-4s routine encounters), Expert Mode (3-6s complex discussions like surgical consent, oncology consultations, chronic condition management)
Offline-first deployment: AI model binaries positioned locally within facility infrastructure
iOS: MLCLLM SDK with Apple Neural Engine acceleration on Silicon devices
Web: WebGPU compute shaders for in-browser inference, zero-server dependency
Distribution: IPFS-hosted binaries with content-addressed verification, single download establishes permanent offline capability
Network independence: Complete operational continuity during internet outages, bandwidth saturation, or facility network maintenance, critical for emergency department 24/7 requirements and rural facility deployments with limited connectivity
Conclusion
The facility transformed language access from a cost center dependent on external coordination into an instantaneous, zero-marginal-cost operational capability while achieving instantaneous language coverage across 100+ languages with 24/7 availability. Privacy architecture simplifies compliance posture through complete on-premises processing, removing third-party data handling from the risk equation.
With this foundation in place, the facility now extends translation capabilities into telehealth delivery channels, patient education material generation, and multi-site deployment across affiliated care networks, scaling language access without scaling costs.

